PIM Integration Patterns That Actually Work in Production
PIM integration looks simple in demos — until attribute mapping breaks your catalog sync at 50,000 SKUs. Learn the production patterns for catalog sync, multi-channel publishing, and the ownership boundaries that prevent silent data corruption.
Written by Artemii Karkusha — Integration Architect
Every eCommerce platform pitch includes the same slide: "Connect your PIM, and product data flows seamlessly to every channel." I've sat through dozens of these demos. They always work perfectly — with 12 products, 4 attributes, and one storefront.
Then you go to production. 50,000 SKUs. 200+ attributes per product. Five storefronts across three countries with different attribute requirements, languages, and compliance rules. And the "seamless flow" becomes the hardest integration problem in your entire architecture.
After 12 years of integration work — including PIM implementations with Akeneo, Salsify, inRiver, and custom-built catalog systems — I've learned that PIM integration is not a data sync problem. It's a data ownership problem. Get the ownership boundaries wrong, and no amount of ETL scripting will save you.
This article covers the production patterns I trust for PIM integration: attribute mapping strategies that don't break at scale, catalog sync architectures that survive 100K+ SKU catalogs, and the multi-channel publishing model that keeps five storefronts consistent without turning your PIM into a bottleneck.
What a PIM Actually Does in an Integration Landscape
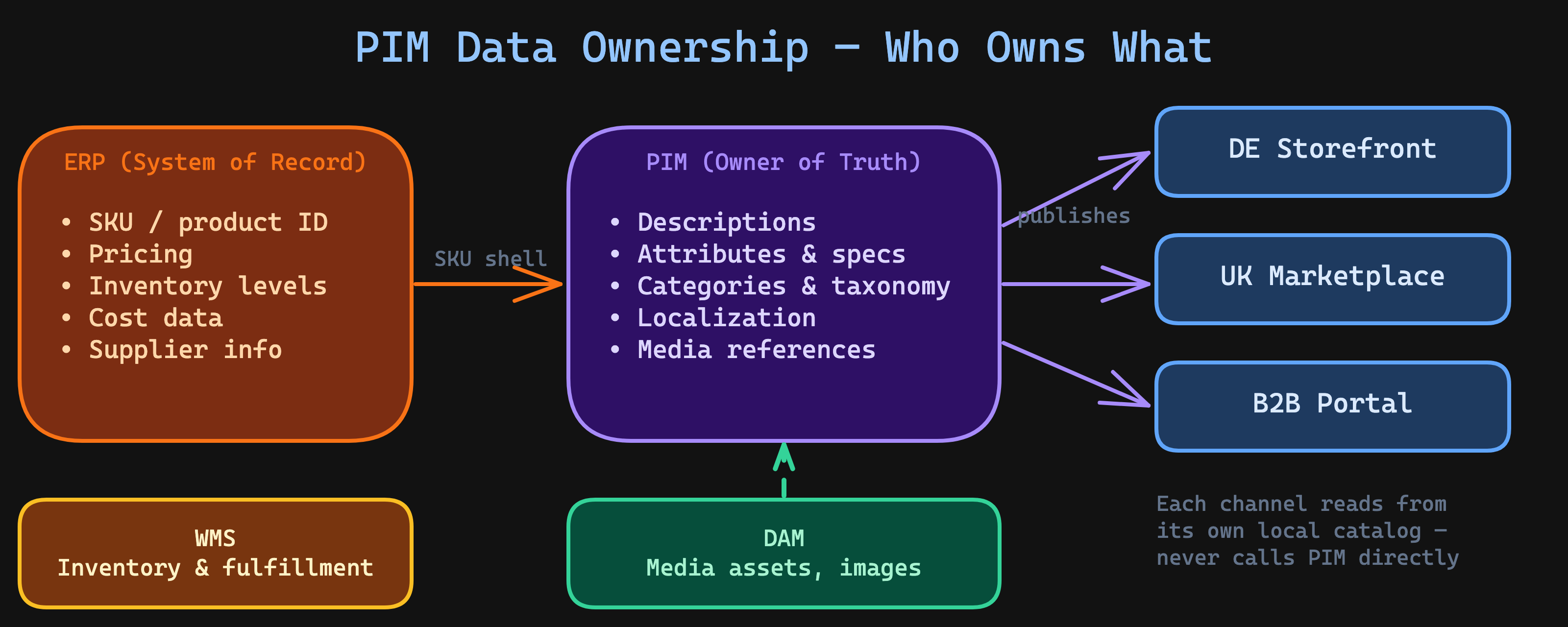
Before diving into patterns, let's be precise about what a PIM is — and isn't — in a production integration architecture.
A Product Information Management system is the system of record for enriched product data. Not raw product data (that's the ERP), not pricing (that's the ERP or pricing engine), not inventory (that's the WMS or ERP). The PIM owns:
- Marketing content: descriptions, selling points, rich media references
- Attribute values: size, color, material, technical specifications
- Taxonomy: category trees, product families, attribute groups
- Localization: translations, locale-specific content
- Channel completeness: which attributes are required for which channel
| Data Domain | System of Record | PIM Role |
|---|---|---|
| SKU / product identity | ERP | Consumer (imports SKU shell) |
| Pricing | ERP / pricing engine | Pass-through or excluded |
| Inventory / stock levels | WMS / ERP | Not involved |
| Product descriptions | PIM | Owner (enrichment happens here) |
| Attributes & specs | PIM | Owner (structured attribute management) |
| Media assets | DAM / PIM | Owner or connector (depends on DAM) |
| Categories & taxonomy | PIM | Owner (category tree management) |
This table is the first conversation I have on every PIM project. When ownership is ambiguous — when the ERP team thinks they own product descriptions, or when the eCommerce team maintains categories directly in Magento — you will get data conflicts. Not maybe. Always.
This is The Ownership Boundary Rule in action: every integration must have a single owner of truth. If everyone owns the product data, no one does.
The Attribute Mapping Problem Nobody Warns You About
Attribute mapping is where PIM integrations go to die. Not because mapping itself is hard — it's because attribute schemas evolve independently across systems, and nobody plans for that.
Here's what happens in practice:
- Day 1: PIM has
color(text). Magento hascolor(dropdown with option IDs). You write a mapper. - Month 3: PIM team adds
color_hexfor the mobile app. The mapper doesn't know about it. Mobile shows no colors. - Month 6: Magento team adds
color_familyfor layered navigation. PIM doesn't have it. Catalog team manually fills it in Magento. Now two systems "own" color data. - Month 12: Someone asks why the German store shows English color names. The mapper was never updated for the new locale scope.
This is schema drift — and it's the number one reason PIM integrations degrade over time.
The mapping contract pattern
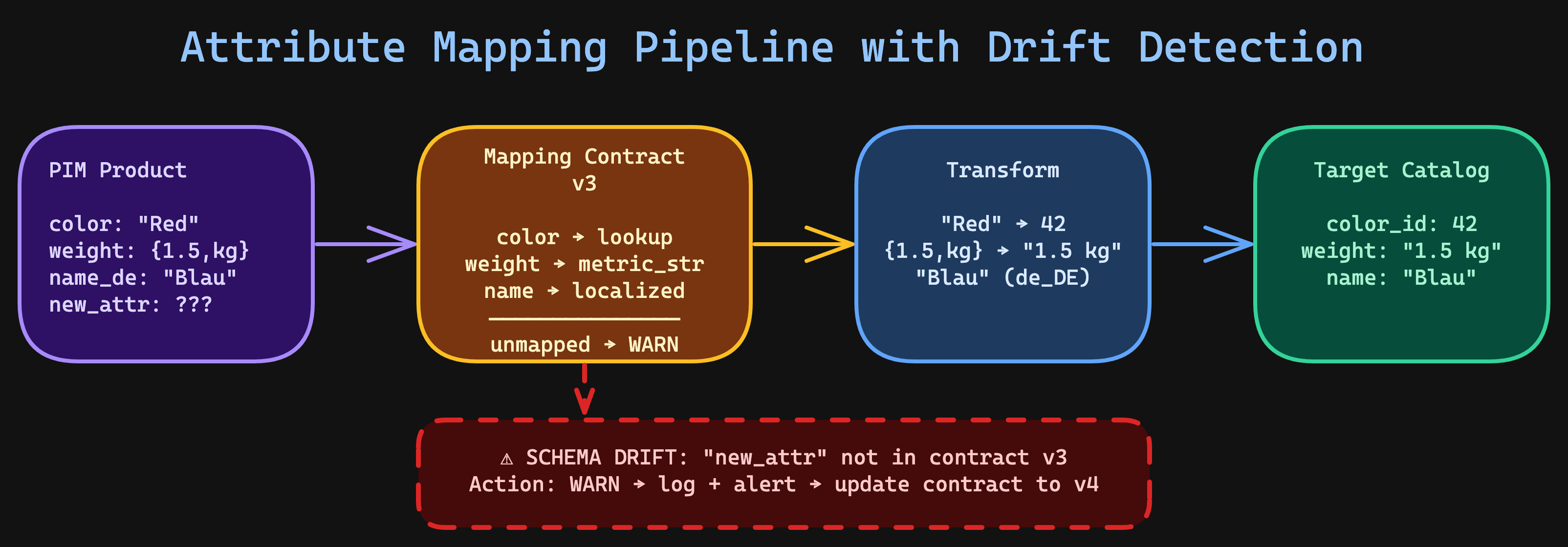
The fix is to treat attribute mapping as a versioned contract, not a hardcoded lookup table. Here's the pattern I use in production:
interface AttributeMapping {
readonly pimAttribute: string;
readonly targetAttribute: string;
readonly targetSystem: string;
readonly transformType: "direct" | "lookup" | "computed" | "localized";
readonly version: number;
readonly required: boolean;
}
interface MappingContract {
readonly contractId: string;
readonly version: number;
readonly sourceSystem: "pim";
readonly targetSystem: string;
readonly mappings: readonly AttributeMapping[];
readonly unmappedStrategy: "skip" | "warn" | "fail";
}
const resolveMappings = (
contract: MappingContract,
pimProduct: PimProduct,
logger: Logger
): MappedAttributes => {
const mapped: Record<string, unknown> = {};
const warnings: string[] = [];
for (const mapping of contract.mappings) {
const sourceValue = pimProduct.attributes[mapping.pimAttribute];
if (sourceValue === undefined || sourceValue === null) {
if (mapping.required) {
warnings.push(
`Required attribute "${mapping.pimAttribute}" missing for SKU ${pimProduct.sku}`
);
}
continue;
}
const transformed = applyTransform(mapping, sourceValue, pimProduct.locale);
mapped[mapping.targetAttribute] = transformed;
}
// Detect unmapped PIM attributes — schema drift signal
const mappedPimAttributes = new Set(
contract.mappings.map((m) => m.pimAttribute)
);
const unmappedAttributes = Object.keys(pimProduct.attributes).filter(
(attr) => !mappedPimAttributes.has(attr)
);
if (unmappedAttributes.length > 0) {
const message = `Schema drift detected: ${unmappedAttributes.length} unmapped attributes for ${pimProduct.sku}`;
if (contract.unmappedStrategy === "fail") {
throw new SchemaDriftError(message, unmappedAttributes);
}
if (contract.unmappedStrategy === "warn") {
logger.warn("schema_drift_detected", {
sku: pimProduct.sku,
unmappedAttributes,
contractVersion: contract.version,
});
}
}
if (warnings.length > 0) {
logger.warn("mapping_warnings", {
sku: pimProduct.sku,
warnings,
contractVersion: contract.version,
});
}
return { attributes: mapped, warnings, unmappedAttributes };
};
Three things that matter here:
- Unmapped attribute detection — when PIM adds a new attribute that isn't in the contract, you know immediately. Not three months later when a customer reports missing data.
- Configurable strategy —
skip,warn, orfail. In development, usefail. In production initial rollout, usewarn. After stabilization, tighten tofailfor required attributes. - Contract versioning — when mappings change, increment the version. Old and new contracts can coexist during migration.
Handling attribute type transformations
The hardest part of attribute mapping isn't the 1:1 fields. It's the type mismatches. PIM systems store data in their own type systems, and target platforms expect entirely different structures.
type TransformFn = (
value: unknown,
locale?: string
) => unknown;
const TRANSFORM_REGISTRY: Record<string, TransformFn> = {
// PIM stores "Red" as text; Magento needs option_id 42
"lookup": (value, _locale) => {
const optionId = optionLookupTable.get(String(value));
if (optionId === undefined) {
throw new TransformError(`No option mapping for value "${value}"`);
}
return optionId;
},
// PIM stores metric as { amount: 1.5, unit: "kg" }; target needs "1.5 kg"
"metric_to_string": (value) => {
const metric = value as { readonly amount: number; readonly unit: string };
return `${metric.amount} ${metric.unit}`;
},
// PIM stores multi-select as ["cotton", "polyester"]; target needs comma-separated
"multi_to_csv": (value) => {
const items = value as readonly string[];
return items.join(", ");
},
// PIM stores localized value as { en_US: "Blue", de_DE: "Blau" }
"localized": (value, locale) => {
const localized = value as Record<string, string>;
const resolved = localized[locale ?? "en_US"];
if (resolved === undefined) {
throw new TransformError(
`No translation for locale "${locale}" in localized attribute`
);
}
return resolved;
},
};
const applyTransform = (
mapping: AttributeMapping,
value: unknown,
locale?: string
): unknown => {
const transform = TRANSFORM_REGISTRY[mapping.transformType];
if (!transform) {
throw new TransformError(
`Unknown transform type: ${mapping.transformType}`
);
}
return transform(value, locale);
};
The transform registry pattern keeps each transformation isolated and testable. When the PIM team changes how they store color data (it happens), you update one transform function — not a 500-line mapping script.
Catalog Sync Patterns: Delta, Full, and Event-Driven
Once attribute mapping is solved, the next question is how to move catalog data from PIM to target channels. There are three patterns, and you'll probably need two of them.
Pattern 1: Delta sync (the workhorse)
Delta sync moves only what changed since the last sync. It's the default pattern for ongoing catalog synchronization.
interface DeltaSyncConfig {
readonly batchSize: number;
readonly maxConcurrent: number;
readonly channelCode: string;
}
interface SyncResult {
readonly synced: number;
readonly skipped: number;
readonly failed: number;
readonly errors: readonly SyncError[];
readonly durationMs: number;
}
const runDeltaSync = async (
pimClient: PimClient,
targetClient: TargetClient,
mapper: AttributeMapper,
config: DeltaSyncConfig,
cursor: SyncCursor,
logger: Logger
): Promise<SyncResult> => {
const start = Date.now();
let synced = 0;
let skipped = 0;
const errors: SyncError[] = [];
// Fetch products modified since last sync
const modifiedProducts = await pimClient.getModifiedProducts({
since: cursor.lastSyncedAt,
channel: config.channelCode,
limit: config.batchSize,
});
if (modifiedProducts.length === 0) {
logger.info("delta_sync_empty", { channel: config.channelCode });
return { synced: 0, skipped: 0, failed: 0, errors: [], durationMs: Date.now() - start };
}
// Filter to channel-complete products only
const publishable = modifiedProducts.filter((p) => p.completeness === 100);
skipped = modifiedProducts.length - publishable.length;
if (skipped > 0) {
logger.info("delta_sync_incomplete_products", {
channel: config.channelCode,
skipped,
skus: modifiedProducts
.filter((p) => p.completeness < 100)
.map((p) => p.sku),
});
}
// Map and push in controlled batches
const batches = chunk(publishable, config.maxConcurrent);
for (const batch of batches) {
const results = await Promise.allSettled(
batch.map(async (product) => {
const mapped = mapper.map(product, config.channelCode);
await targetClient.upsert(mapped);
return product.sku;
})
);
for (const result of results) {
if (result.status === "fulfilled") {
synced++;
} else {
errors.push({
sku: "unknown",
error: result.reason instanceof Error ? result.reason.message : String(result.reason),
});
}
}
}
const durationMs = Date.now() - start;
logger.info("delta_sync_complete", {
channel: config.channelCode,
synced,
skipped,
failed: errors.length,
durationMs,
});
return { synced, skipped, failed: errors.length, errors, durationMs };
};
Delta sync relies on the PIM's ability to track modification timestamps. Most modern PIMs (Akeneo, Salsify, inRiver) support this natively. Legacy systems may need a change-tracking layer — a trigger-based changelog table or a CDC (Change Data Capture) stream.
Pattern 2: Full sync (the safety net)
Full sync re-publishes the entire catalog. It's slow, resource-intensive, and absolutely necessary.
Why? Because delta sync accumulates drift. A failed batch that wasn't retried. An attribute mapping change that only applies going forward. A manual edit in the storefront that overwrites synced data. Over weeks and months, the target catalog quietly diverges from the PIM.
Full sync is the correction mechanism. It runs in the publisher layer — the same component that drives delta sync — and writes to the channel-local catalog store that sits next to the commerce platform. The storefront never participates; PIM is only ever read via its bulk export interface:
interface FullSyncRun {
readonly runId: string; // unique per execution, e.g. UUID
readonly startedAt: string; // ISO timestamp
readonly channelCode: string;
}
interface FullSyncResult {
readonly runId: string;
readonly totalSynced: number;
readonly orphansDisabled: number;
readonly durationMs: number;
}
const runFullSync = async (
pimExport: PimExportReader, // streams/pages PIM's bulk export
channelCatalog: ChannelCatalogStore, // channel-local, commerce-adjacent
mapper: AttributeMapper,
run: FullSyncRun,
logger: Logger
): Promise<FullSyncResult> => {
const start = Date.now();
let totalSynced = 0;
// 1) Stream the PIM export in pages. Tag every upserted row with the
// current runId so we can identify orphans by absence, not by diff.
let cursor: string | null = null;
do {
const page = await pimExport.nextPage({
channel: run.channelCode,
completenessMin: 100,
cursor,
limit: 500,
});
const mapped = page.products.map((product) => ({
...mapper.map(product, run.channelCode),
syncRunId: run.runId,
syncedAt: run.startedAt,
}));
// Idempotent bulk upsert keyed on (sku, channel).
// A retried page never produces duplicate rows.
await channelCatalog.bulkUpsert(mapped);
totalSynced += mapped.length;
cursor = page.nextCursor;
} while (cursor !== null);
// 2) Orphan detection via watermark: anything in the channel catalog
// NOT tagged with the current runId is no longer in the PIM's
// publishable set for this channel. Disable — don't delete.
const orphansDisabled = await channelCatalog.disableRowsNotIn({
syncRunId: run.runId,
});
const durationMs = Date.now() - start;
logger.info("full_sync_complete", {
runId: run.runId,
channel: run.channelCode,
totalSynced,
orphansDisabled,
durationMs,
});
return { runId: run.runId, totalSynced, orphansDisabled, durationMs };
};
Three details that matter in production:
- Full sync writes to the channel-local catalog, not to the storefront or back into the PIM. The publisher reads PIM's bulk export once and pushes into a store that lives next to the commerce platform. The storefront never sees the sync; its reads stay local and fast throughout.
- Orphan detection via watermark, not diff. Loading every target SKU into memory to compare against the PIM list stops working somewhere between 50k and 100k rows. Tag every row with the current
syncRunId, then disable anything not tagged in a single SQL statement. Disable, don't delete — you want a human to review before permanent removal. - Schedule wisely — run full sync weekly during off-peak hours. Even with streaming pagination, a 50,000 SKU full sync takes 30–120 minutes depending on attribute count and target throughput. Don't run it during peak traffic.
Pattern 3: Event-driven sync (the accelerator)
Event-driven sync uses PIM webhooks or message queues to push changes in near-real-time. It's the fastest pattern — and the most complex.
| Pattern | Latency | Complexity | Best For |
|---|---|---|---|
| Delta sync | Minutes (cron interval) | Low | Default choice. Works with any PIM. |
| Full sync | Hours (full catalog) | Low | Weekly correction. Drift recovery. |
| Event-driven | Seconds | High | High-frequency catalog changes, multi-channel real-time. |
My recommendation: start with delta sync + weekly full sync. Add event-driven only when the business proves that 5-minute latency isn't fast enough. Most catalog updates — new descriptions, attribute changes, media updates — don't need to be live in 3 seconds.
This is The Real-Time Illusion applied to PIM: "Real-time" catalog sync feels good in demos. Delta sync with 5-minute intervals survives Black Friday.
Multi-Channel Publishing: The Architecture That Scales
Multi-channel publishing is where PIM earns its keep — or becomes the bottleneck. The pattern matters enormously.

The wrong way: PIM as the API gateway
I've seen this architecture too many times:
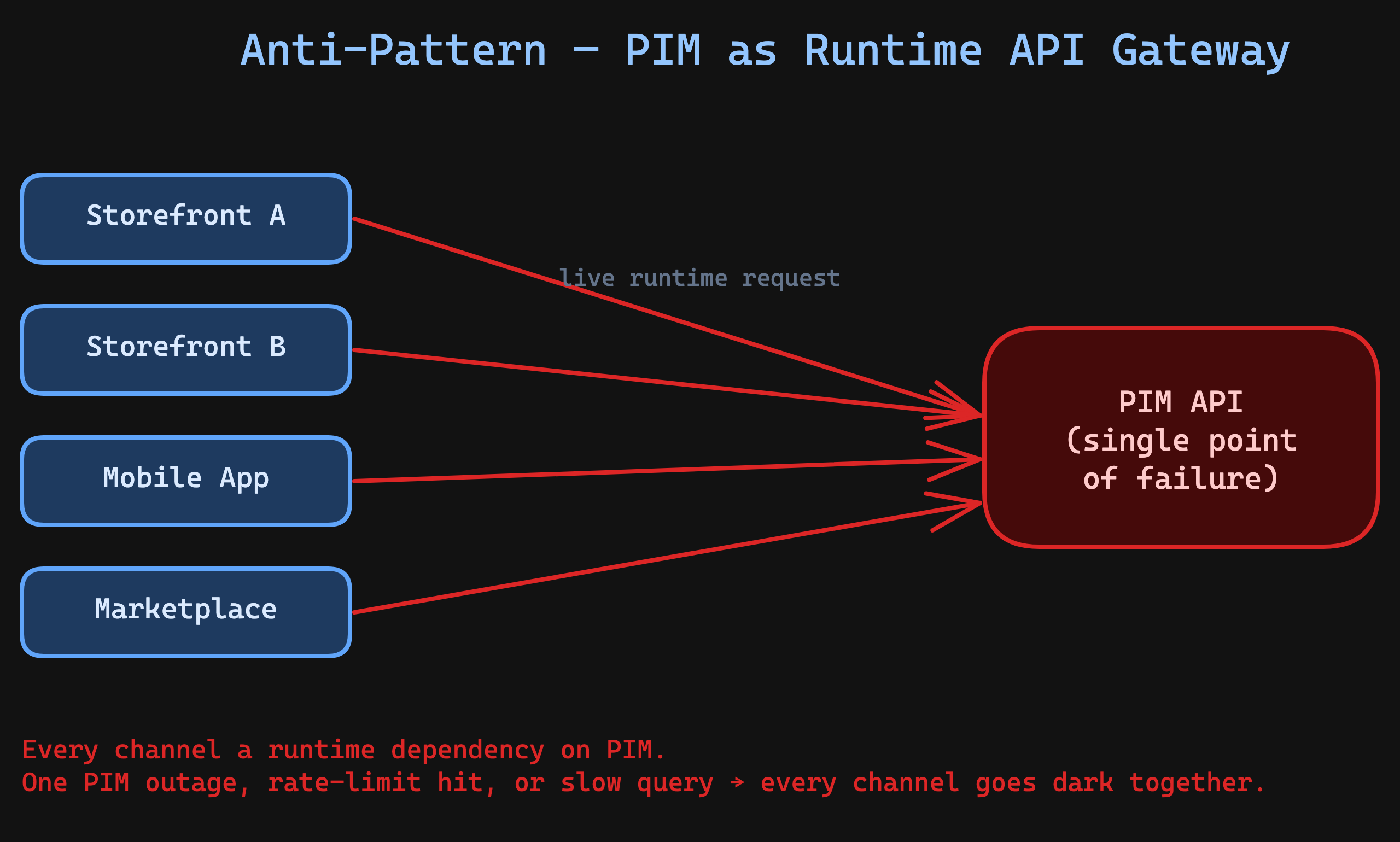
Every channel hits the PIM directly. The PIM becomes a runtime dependency for every storefront. When it goes down — and it will — every channel goes dark simultaneously.
This violates The Aggregation First Rule: consumers should request already-assembled data, not fetch it from the source system on every request.
The right way: PIM as a publisher
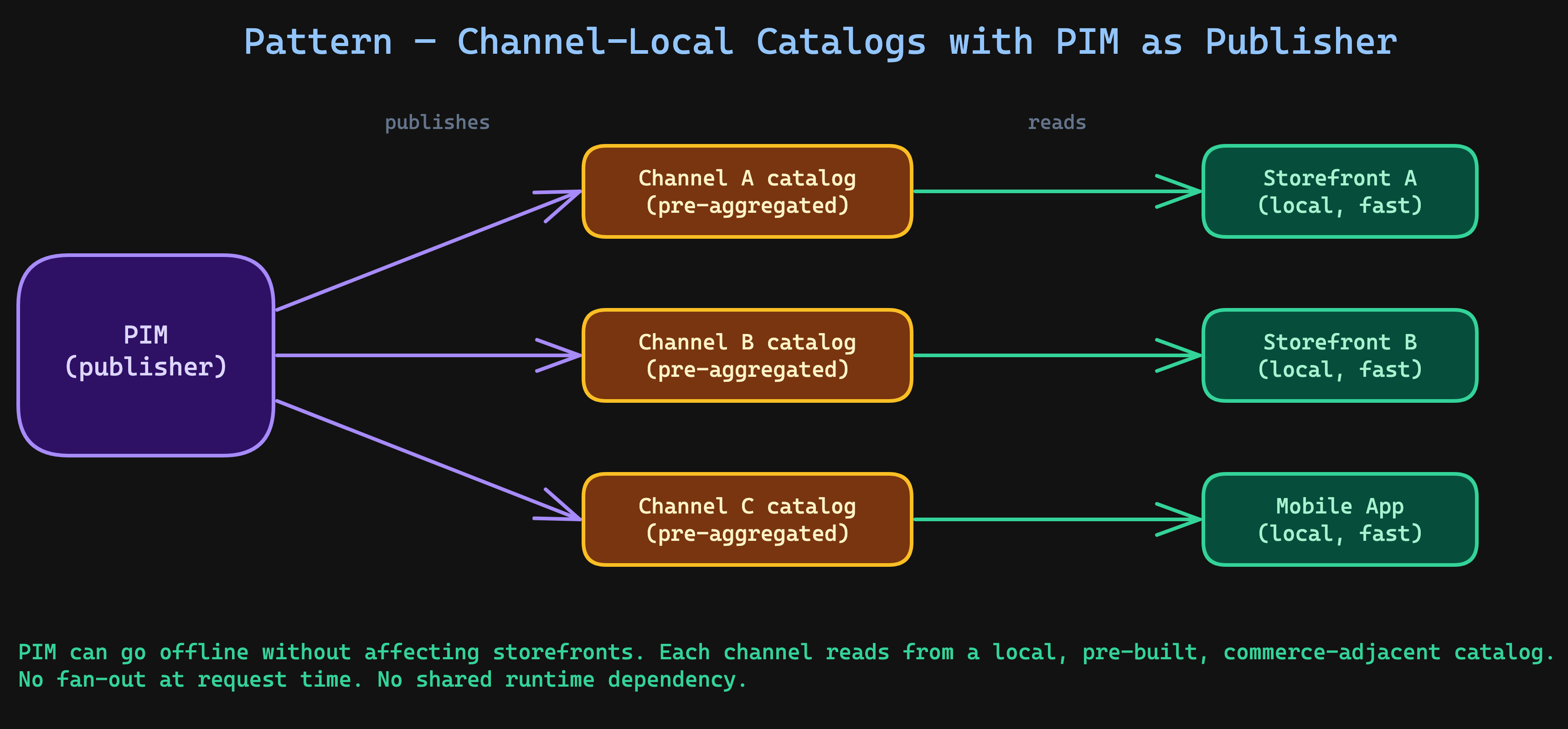
Each channel gets its own pre-built catalog — a denormalized, channel-specific dataset that lives next to the commerce platform, optimized for that channel's query patterns. The PIM pushes data out on its own cadence; channels never call back in at request time.
interface ChannelCatalog {
readonly channelCode: string;
readonly locale: string;
readonly currency: string;
readonly attributeScope: readonly string[];
readonly categoryTree: string;
}
interface PublishPipeline {
readonly channel: ChannelCatalog;
readonly mapper: AttributeMapper;
readonly target: TargetClient;
readonly filters: readonly ProductFilter[];
}
const publishToChannel = async (
pipeline: PublishPipeline,
product: PimProduct,
logger: Logger
): Promise<PublishResult> => {
// Step 1: Check channel completeness
const completeness = calculateCompleteness(
product,
pipeline.channel.attributeScope
);
if (completeness < 100) {
logger.info("publish_skipped_incomplete", {
sku: product.sku,
channel: pipeline.channel.channelCode,
completeness,
missingAttributes: getMissingAttributes(
product,
pipeline.channel.attributeScope
),
});
return { status: "skipped", reason: "incomplete" };
}
// Step 2: Apply channel-specific filters
for (const filter of pipeline.filters) {
if (!filter.passes(product)) {
return { status: "filtered", reason: filter.name };
}
}
// Step 3: Map attributes for this channel's scope
const mapped = pipeline.mapper.map(product, pipeline.channel.channelCode);
// Step 4: Resolve locale-specific content
const localized = resolveLocale(mapped, pipeline.channel.locale);
// Step 5: Publish to channel's local catalog
await pipeline.target.upsert(localized);
return { status: "published" };
};
The key insight: each channel defines its own attribute scope. The German B2B storefront needs technical_data_sheet, hazmat_class, and customs_tariff_number. The consumer mobile app needs short_description, lifestyle_images, and color_swatch. Same product, different data.
The PIM's job is to hold all of this and publish the right slice to the right channel. The channel's job is to serve it fast.
Production Pattern
On a Salsify-to-Shopware integration for a consumer electronics brand, we publish to 4 channels: DE storefront (German, EUR), AT storefront (German, EUR, different tax rules), UK marketplace (English, GBP), and a B2B portal (English, EUR, extended specs). Each channel has its own attribute scope, category tree, and completeness rules. Delta sync runs every 10 minutes per channel. Full sync runs Sunday 2 AM. The total catalog is 35,000 SKUs. Delta sync averages 200-400 products per cycle. No channel has ever served stale data for more than 12 minutes.
The Aggregation Trap: When Your PIM Becomes the Bottleneck
Here's the pattern I see repeatedly in mid-market eCommerce: the PIM starts as a product data manager, then gradually becomes the integration hub for everything.
First, it manages product descriptions. Then someone adds pricing rules. Then someone connects the DAM through the PIM. Then inventory availability flags get pushed through the PIM pipeline. Before you know it, the PIM sync is a 4-hour job because it's aggregating data from 6 different systems before publishing.
This is The Data Gravity Rule working against you: data gravitates toward wherever it's processed, and the PIM becomes a black hole that absorbs everything.
Signs you've fallen into the aggregation trap
- PIM sync takes longer every month
- Adding a new attribute requires changes to 3+ integration scripts
- The PIM team is a bottleneck for storefront feature releases
- "Let's just add it to the PIM feed" becomes the default answer
- Sync failures cascade across unrelated data domains
The escape pattern: separate the concerns
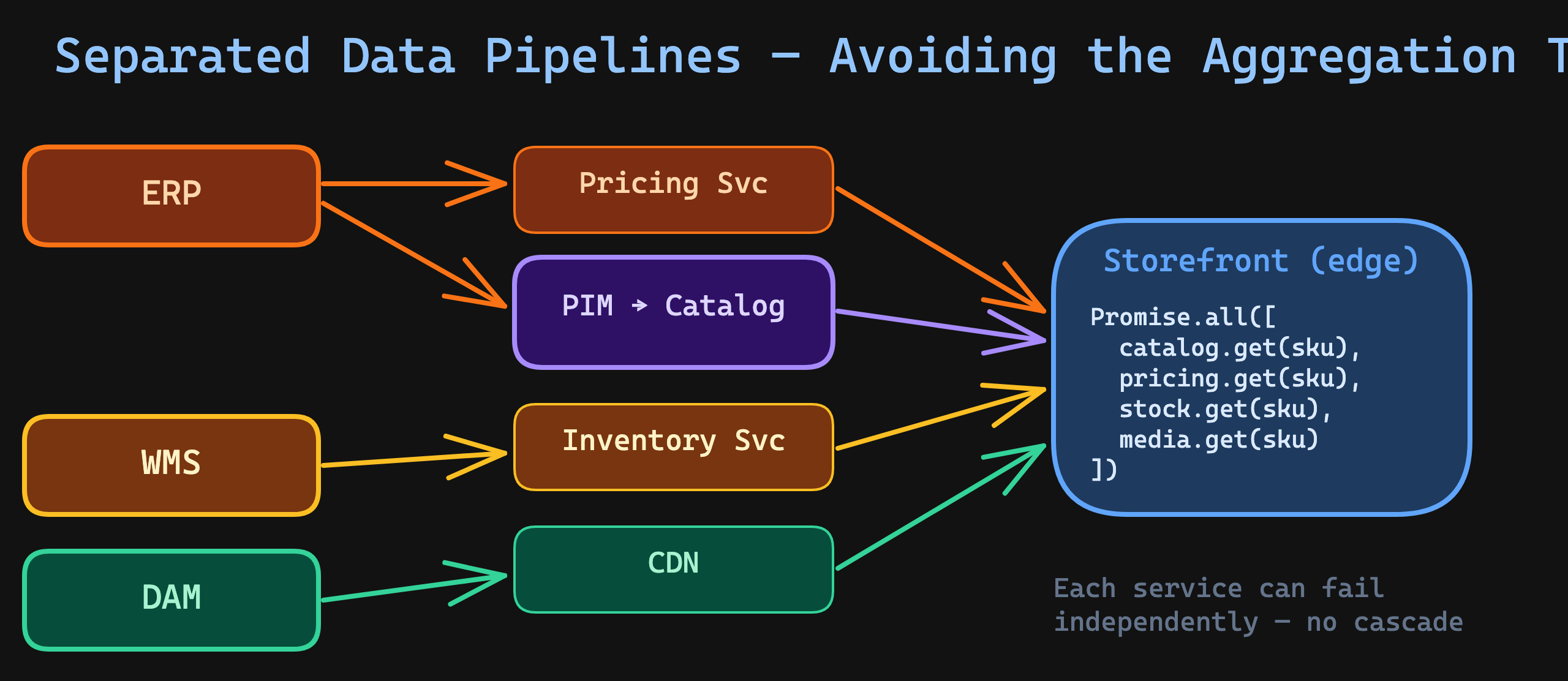
ERP ──────→ Product shell (SKU, status) ──→ PIM ──→ Enriched catalog ──→ Channels
ERP ──────→ Pricing ─────────────────────────────→ Pricing service ────→ Channels
WMS ──────→ Inventory ───────────────────────────→ Inventory service ──→ Channels
DAM ──────→ Media assets ────────────────────────→ CDN ────────────────→ Channels
Each data domain flows through its own pipeline. The PIM handles what it's good at — enriched product content. Pricing, inventory, and media travel independently.
But — and this is where most "aggregation at the edge" articles get it wrong — the storefront must not fan out to four services on every request. Parallel fetches at the edge look clean in a diagram and break in production: you inherit the slowest dependency's p99 on every render, you pay four network hops per page, and a partial outage in any single domain degrades every product page simultaneously. That's the same runtime coupling as the "PIM as gateway" anti-pattern — just spread across more services.
This is the second half of The Aggregation First Rule: aggregation belongs out of the request path, not in it.
The Product Page Service: commerce-adjacent, already composed
The pattern that survives production is a Product Page Service that lives inside the commerce platform's boundary — same region, same cluster, same database tier — and owns a pre-composed product page document for every (sku, channel) pair. Catalog, pricing, inventory, and media changes flow into it as events from each domain's own pipeline. The storefront performs exactly one read.
interface ProductPageDocument {
readonly sku: string;
readonly channel: string;
readonly catalog: CatalogProjection;
readonly pricing: PricingProjection;
readonly inventory: InventoryProjection;
readonly media: MediaProjection;
readonly sourceVersions: Record<string, number>; // per-domain version
readonly readiness: ReadinessFlags; // which domains have projected
readonly updatedAt: string;
}
interface ProductPageService {
readonly get: (
sku: string,
channel: string
) => Promise<ProductPageDocument | null>;
}
// Storefront: a single local read. Latency is bounded by the local store,
// not by the slowest upstream domain.
const renderProductPage = async (
service: ProductPageService,
sku: string,
channel: string
): Promise<RenderedPage> => {
const doc = await service.get(sku, channel);
if (doc === null) return renderNotFound();
return renderFromDocument(doc);
};
The document stays fresh via independent, idempotent, version-aware event consumers — one per source domain:
interface DomainEvent {
readonly type: "catalog" | "pricing" | "inventory" | "media";
readonly sku: string;
readonly channel: string;
readonly sourceVersion: number; // monotonically increasing at the source
readonly occurredAt: string;
readonly payload: unknown;
}
const applyEvent = async (
store: ProductPageStore,
event: DomainEvent,
logger: Logger
): Promise<void> => {
const current = await store.get(event.sku, event.channel);
const lastVersion = current?.sourceVersions[event.type] ?? 0;
// Out-of-order, replayed, or duplicate events all no-op here.
// The projection is safe to feed from at-least-once delivery.
if (event.sourceVersion <= lastVersion) {
logger.debug("event_ignored_stale", {
sku: event.sku,
channel: event.channel,
type: event.type,
lastVersion,
incoming: event.sourceVersion,
});
return;
}
const next = projectEvent(current, event);
await store.upsert(next);
logger.info("projection_updated", {
sku: event.sku,
channel: event.channel,
type: event.type,
version: event.sourceVersion,
});
};
Four properties that matter in production:
- One read at request time. The storefront never calls pricing, inventory, or media directly. A single query against a local store — often the same Postgres instance as the commerce platform, or a Redis/KV tier sitting next to it.
- Bounded p99, independent failure domains. If pricing's event pipeline is backed up, prices go stale by seconds; the product page still renders. The storefront's latency is decoupled from every upstream's worst day.
- Versioned idempotency. Each source domain stamps its own monotonically-increasing
sourceVersion. Out-of-order delivery, duplicate events, and replayed backfills all no-op automatically — no distributed locks, no orchestrator. - Readiness flags for partial projections. When a new SKU is first published, the catalog event usually arrives before pricing or inventory. The document carries
readiness: { catalog: true, pricing: false, ... }so the render layer can show "Contact for pricing" or hide the buy button until the projection is complete — instead of blocking a render that may never fully hydrate.
And a reconciliation job — nightly or weekly — rebuilds the projection from each domain's snapshot endpoint. This catches the small fraction of events that get lost or mis-ordered in practice. It's the same safety-net pattern as the Pattern 2 full sync: events for speed, periodic rebuild for correctness.
Implementation Checklist
Ownership & contracts
- Document which system owns each product data domain (use the table from this article as a starting point)
- Define a versioned attribute mapping contract between PIM and each target
- Configure unmapped attribute detection with
warnstrategy in production - Set up alerts for schema drift (new unmapped attributes)
- Establish a change notification process: PIM team notifies integration team before adding attributes
Catalog sync
- Implement delta sync as the primary sync mechanism (5-15 minute intervals)
- Implement weekly full sync for drift correction
- Add orphan detection to full sync (disable, don't delete)
- Log every sync cycle: duration, record count, errors, skipped products
- Set up monitoring dashboards for sync health (frequency, duration trends, error rates)
Multi-channel publishing
- Define attribute scope per channel (which attributes go where)
- Define completeness rules per channel (minimum required attributes)
- Build channel-specific publish pipelines with independent failure isolation
- Never expose PIM API directly to storefronts — publish to channel-local catalogs
- Test with production-scale data (not 12 demo products)
Avoiding the aggregation trap
- Keep pricing, inventory, and media outside the PIM sync pipeline
- Each data domain gets its own integration path to channels
- Storefront performs a single read against a commerce-adjacent Product Page Service; aggregation happens out of the request path via event projections, not via parallel fetches at render time
- PIM sync duration should remain stable as catalog grows — if it increases monthly, you're aggregating too much
The Integration Maestro Perspective
"If everyone owns the data, no one does." — The Ownership Boundary Rule
PIM integration is fundamentally an ownership problem disguised as a data sync problem. The teams that get it right start by drawing boundaries: what the PIM owns, what it doesn't, and what happens when those boundaries are violated.
The patterns in this article — versioned mapping contracts, delta + full sync, channel-specific publishing, separated data domains — aren't clever abstractions. They're the result of watching PIM integrations fail in production and rebuilding them with explicit ownership at every boundary.
If you're starting a PIM integration, start with the ownership table. Not the API documentation, not the data model, not the ETL scripts. The ownership table. Everything else follows from that.
Related Integration Maestro Rules:
- The Ownership Boundary Rule — every integration must have a single owner of truth
- The Data Gravity Rule — data should be consumed close to where it changes
- The Aggregation First Rule — consumers should request already-assembled data
- The Real-Time Illusion — "real-time" is a business requirement, not a technical one
Related articles:
- How Slow ERP Sync Silently Kills eCommerce Revenue — the ERP side of the product data pipeline
- Polling vs Webhooks: How to Choose the Right Integration Trigger — trigger strategy for catalog sync
- Idempotency: The #1 Rule of Safe Integrations — why your PIM sync handlers must be idempotent
Have a PIM integration challenge? I've helped teams untangle Akeneo, Salsify, and custom catalog systems across dozens of storefronts. Let's talk architecture.
Enjoying this article?
Get more deep dives on integration architecture delivered to your inbox.

Integration Architect
Artemii Karkusha is an integration architect focused on ERP, eCommerce, and high-load system integrations. He writes about integration failures, architectural trade-offs, and performance patterns.
Came from LinkedIn or X? Follow me there for more quick insights on integration architecture, or subscribe to the newsletter for the full deep dives.