Polling vs Webhooks: How to Choose the Right Integration Trigger
The polling vs webhooks debate has a clear winner in most integration projects — and it's neither. Learn the real trade-offs, the hybrid pattern that survives production, and a 5-question decision framework for choosing the right trigger strategy.
Written by Artemii Karkusha — Integration Architect
The polling vs webhooks debate is one of the first architectural decisions in any integration project. And most teams get it wrong.
Webhooks are treated as the modern default — event-driven, real-time, elegant. Polling is dismissed as legacy, wasteful, and slow. But after building integrations across SAP, Magento, Shopify, Akeneo, and dozens of custom systems, I've learned that the polling vs webhooks choice is more nuanced than "new vs old." The trigger strategy is as important as the data mapping itself.
Choose wrong, and you get silent data loss, phantom duplicates, or overengineered infrastructure for what should be a simple nightly sync.
This article breaks down polling vs webhooks from a production perspective — not theory. You'll get a comparison matrix, a decision framework, the hybrid pattern I trust with business-critical data, and the observability setup that tells you when something breaks.
What Polling Actually Is (and Why It's Not Dead)
Polling is client-initiated data retrieval on a schedule. Your system asks: "Has anything changed since I last checked?"
The pattern is straightforward:
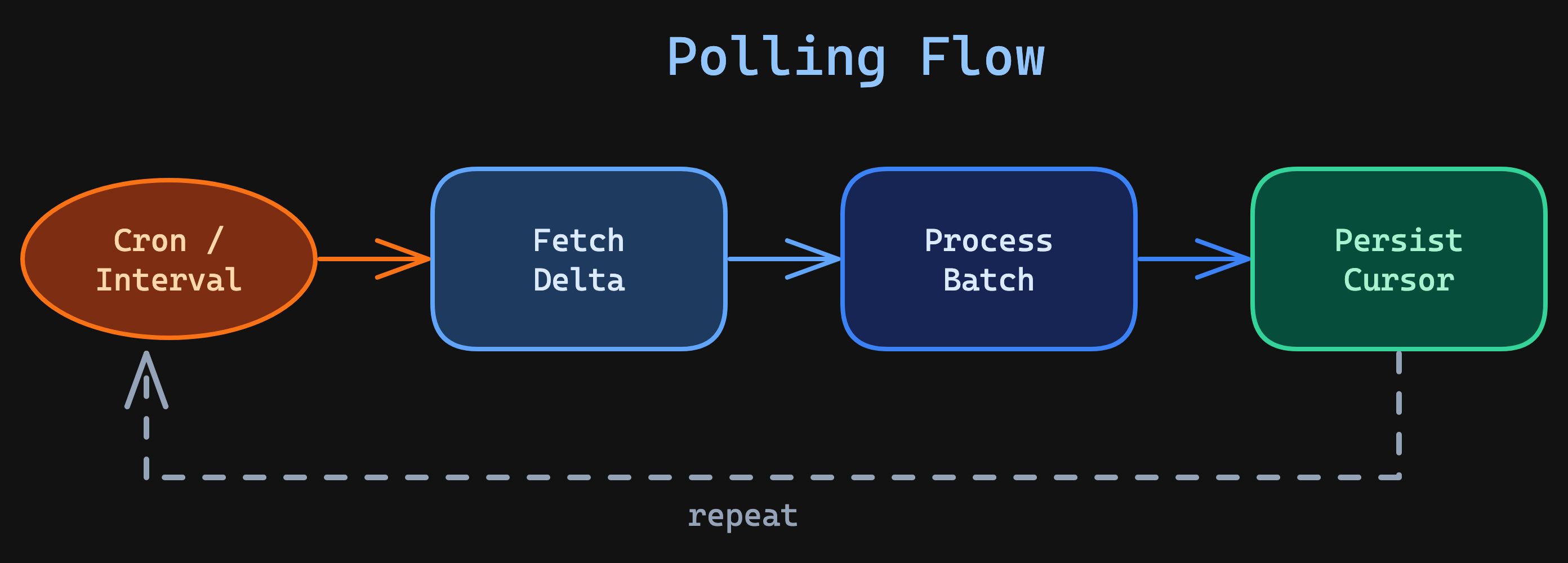
Here's what a production-grade polling loop looks like — with cursor persistence, batch processing, and structured logging:
interface PollCursor {
readonly lastSyncedAt: string;
readonly lastProcessedId: string;
}
interface PollResult {
readonly cursor: PollCursor;
readonly processed: number;
readonly durationMs: number;
}
const pollForChanges = async (
cursor: PollCursor,
cursorStore: CursorStore,
logger: Logger
): Promise<PollResult> => {
const start = Date.now();
const response = await erpClient.getModifiedOrders({
modifiedSince: cursor.lastSyncedAt,
afterId: cursor.lastProcessedId,
limit: 200,
orderBy: "modified_at",
});
if (response.orders.length === 0) {
logger.info("poll_cycle_empty", { cursor, durationMs: Date.now() - start });
return { cursor, processed: 0, durationMs: Date.now() - start };
}
// Process in batches, not one-by-one
await processBatch(response.orders);
const lastOrder = response.orders[response.orders.length - 1];
const newCursor: PollCursor = {
lastSyncedAt: lastOrder.modifiedAt,
lastProcessedId: lastOrder.id,
};
// Persist cursor AFTER successful processing
await cursorStore.save(newCursor);
const durationMs = Date.now() - start;
logger.info("poll_cycle_complete", {
processed: response.orders.length,
cursor: newCursor,
durationMs,
});
return { cursor: newCursor, processed: response.orders.length, durationMs };
};
Three details that matter in production:
- Immutable cursor — each poll returns a new cursor object, never mutating the previous state.
- Cursor persisted after processing — if the process crashes mid-batch, the next run re-processes from the last saved cursor. No data loss.
- Structured logging — every cycle logs duration, record count, and cursor position. When polling vs webhooks reliability is questioned, these logs are the evidence.
Why ERP systems often only support polling
If you've integrated with SAP, Infor, Epicor, or Microsoft Dynamics, you already know: most ERP systems don't fire webhooks. They expose BAPI calls, OData endpoints, or custom RFC interfaces that you query on demand. The system of record waits for you to ask.
This isn't a limitation — it's a design choice. ERPs prioritize transactional consistency over push-based notifications. They're built for batch operations, not event streaming. When evaluating polling vs webhooks for ERP integrations, polling often isn't a compromise — it's the correct architectural fit.
When polling wins
Polling is the stronger choice when:
- The source system doesn't support webhooks — most ERPs, legacy databases, SFTP-based feeds
- Data changes are low-frequency — nightly price list updates, weekly catalog refreshes
- You need full control over timing — batch windows, rate-limited APIs, resource-constrained environments
- Network topology is restrictive — no inbound firewall rules needed, no public endpoints to expose
- Debugging is critical — you can replay any sync cycle by re-running the poll with the same cursor
- Ordering matters — you control the sequence; no out-of-order event delivery
What Webhooks Actually Are (and Why They're Not Magic)
Webhooks flip the model. Instead of asking, you listen. The source system pushes an HTTP POST to your endpoint when something happens.
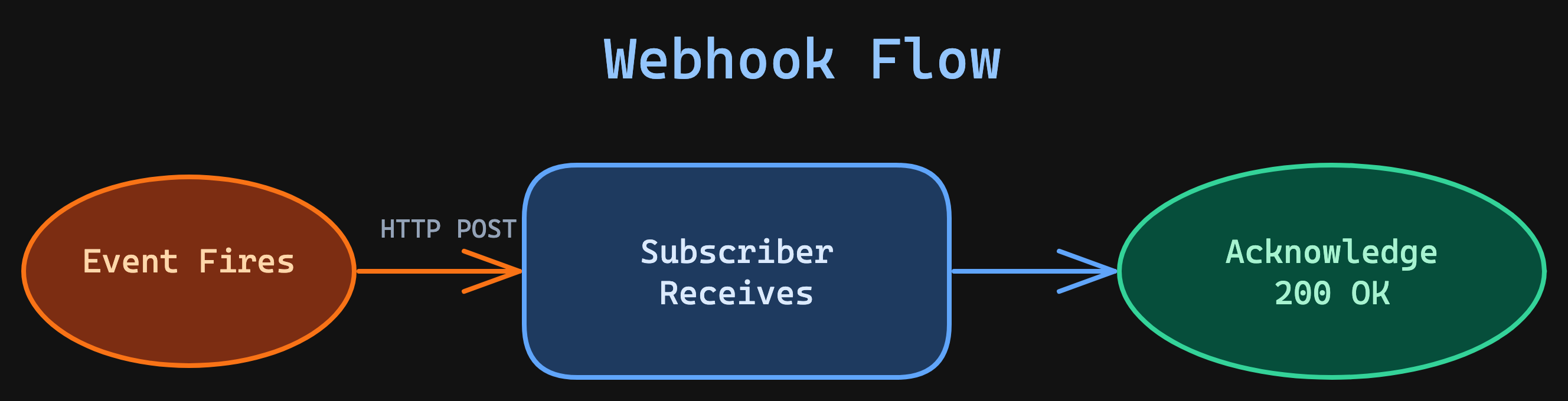
Here's a production webhook handler with signature validation, timeout protection, and queue-based processing:
import { createHmac, timingSafeEqual } from "crypto";
interface WebhookPayload {
readonly eventId: string;
readonly eventType: string;
readonly occurredAt: string;
readonly data: Record<string, unknown>;
}
const handleWebhook = async (
request: Request,
secret: string,
queue: MessageQueue
): Promise<Response> => {
// Step 1: Validate signature FIRST — reject before parsing body
const signature = request.headers.get("x-webhook-signature") ?? "";
const body = await request.text();
const expected = createHmac("sha256", secret).update(body).digest("hex");
const isValid = timingSafeEqual(
Buffer.from(signature),
Buffer.from(expected)
);
if (!isValid) {
return new Response("Invalid signature", { status: 401 });
}
// Step 2: Parse and enqueue — never process inline
const payload: WebhookPayload = JSON.parse(body);
// Enqueue to a durable queue (BullMQ, RabbitMQ, SQS, etc.)
await queue.publish("integration.events", {
eventId: payload.eventId,
eventType: payload.eventType,
payload: payload.data,
receivedAt: new Date().toISOString(),
});
// Step 3: Respond 200 IMMEDIATELY
return new Response("OK", { status: 200 });
};
Three critical details:
- Signature validation uses
timingSafeEqual— not a string comparison — to prevent timing attacks. - Enqueue to a durable queue, not an in-memory array. If your process restarts, in-memory events are gone. BullMQ (Redis-backed), RabbitMQ, or SQS give you durability.
- Respond 200 before processing. Never do business logic inside the webhook handler. The provider's retry timeout is typically 5-30 seconds — any processing longer than that triggers a retry, which triggers a duplicate.
The hidden complexity most teams miss
Webhooks feel simple until they break in production. Here's what the docs don't emphasize — and what makes the polling vs webhooks trade-off much closer than it appears:
Delivery is NOT guaranteed. If your server is down when the webhook fires, the event may be lost entirely. Some providers retry for hours. Others retry once and give up. Some don't retry at all.
Ordering is NOT guaranteed. An order.updated event might arrive before order.created if the provider processes events in parallel. Your handler must tolerate out-of-order delivery — or implement a resequencing buffer.
Deduplication is YOUR responsibility. Providers may send the same event multiple times — during retries, during failover, or simply due to bugs. If you process the same order.paid event twice, you've charged the customer twice. This directly connects to The Idempotency Mandate — if it can retry, it must be idempotent.
Retry storms can DDoS your own system. When your handler returns 500 errors, the provider retries. If the failure is systemic (database down, deployment in progress), retries accumulate. Suddenly you're receiving thousands of duplicate events per minute — from your own integration partner. This is The Retry Storm Effect in action.
The Comparison Matrix
Before deciding between polling vs webhooks, understand the trade-offs across every dimension that matters in production:
| Criteria | Polling | Webhooks |
|---|---|---|
| Latency | Minutes to hours | Seconds |
| Implementation complexity | Low | Medium-High |
| Reliability | High (self-healing) | Depends on handler quality |
| ERP compatibility | Universal | Rare |
| Firewall / network | No inbound needed | Requires public endpoint |
| Debugging | Easy (replay anytime) | Hard (one-shot delivery) |
| Cost at scale | Higher API calls | Lower API calls |
| Data ordering | Guaranteed (you control) | Not guaranteed |
| Missed events | None (you re-poll) | Possible without retry/DLQ |
| Scalability | Linear (more data = more calls) | Event-proportional |
| Observability | Simple (you control the loop) | Complex (external push, async processing) |
The pattern is clear: polling gives you control and reliability at the cost of latency. Webhooks give you speed at the cost of complexity, failure handling, and observability.
The Hybrid Pattern — The Real Answer
Here's what 12 years of integration work has taught me: in production, the polling vs webhooks answer is almost always hybrid.
Use webhooks for the trigger. Use polling for verification. This is the belt-and-suspenders approach, and it's the only strategy I trust with business-critical data.
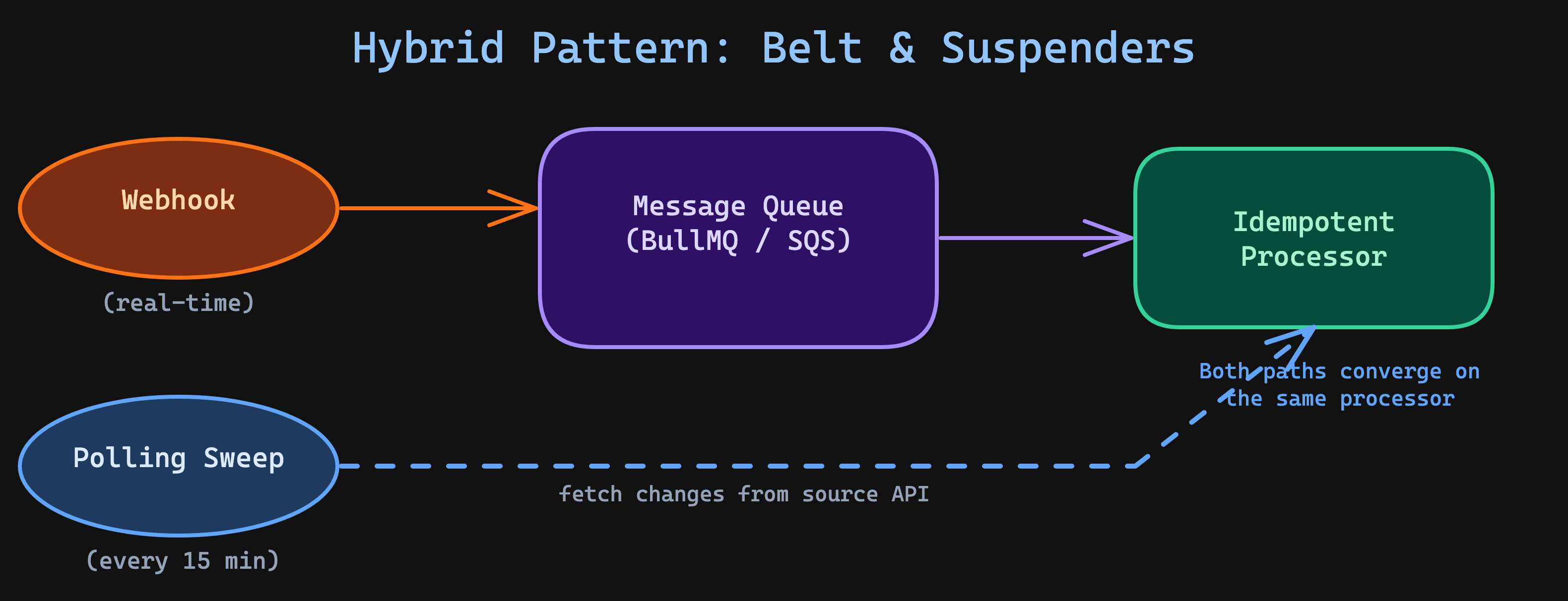
Both paths — webhook-triggered and polling-recovered — converge on the same idempotent processor. No duplicate business logic. The processor checks whether each event has already been handled before acting on it.
Here's the reconciliation layer that ties it together:
interface ReconciliationReport {
readonly processed: number;
readonly alreadyHandled: number;
readonly recovered: number;
readonly durationMs: number;
}
const runReconciliationSweep = async (
since: Date,
processedEvents: EventStore,
logger: Logger
): Promise<ReconciliationReport> => {
const start = Date.now();
let alreadyHandled = 0;
let recovered = 0;
// Stream changes from source — don't load everything into memory
for await (const page of sourceApi.streamChangesSince(since, { pageSize: 200 })) {
for (const change of page) {
const wasHandled = await processedEvents.has(change.id);
if (wasHandled) {
alreadyHandled += 1;
continue;
}
// This change was missed by webhooks — recover it
await idempotentProcessor.process(change);
recovered += 1;
logger.warn("reconciliation_recovery", {
changeId: change.id,
changeType: change.type,
originalTimestamp: change.occurredAt,
});
}
}
const report: ReconciliationReport = {
processed: alreadyHandled + recovered,
alreadyHandled,
recovered,
durationMs: Date.now() - start,
};
logger.info("reconciliation_complete", report);
return report;
};
Key improvements over a naive implementation:
- Streaming pagination — uses
streamChangesSincewith an async iterator instead of loading all changes into memory. For a reconciliation window of 1 hour, this could be thousands of records. - Event store lookup — checks
processedEvents.has(change.id)to skip already-handled events, rather than re-processing everything. - Structured logging on recovery — when the sweep catches a missed event, it logs a warning. If you see these warnings frequently, your webhook infrastructure has a reliability problem.
Production Pattern
A self-hosted Adobe Commerce store I integrated with Akeneo PIM uses Akeneo's event subscription API to fire webhooks on product updates — pushing enriched product data (descriptions, attributes, media assets) into Adobe Commerce in near real-time via a custom import module. Every 15 minutes, a polling sweep queries Akeneo's Product API (GET /api/rest/v1/products-uuid?search={"updated":[{"operator":"SINCE LAST N DAYS","value":1}]}) for products modified in the last day. In the first month, the sweep recovered 47 product updates that Akeneo webhooks had silently dropped after a PIM re-indexing job temporarily saturated the outbound event queue. Without the polling fallback, those products would have gone live on the storefront with stale descriptions and missing attributes — and nobody would have noticed until a customer flagged a wrong specification.
Why this relates to The Data Gravity Rule
The Data Gravity Rule states that data should be consumed close to where it changes. The hybrid polling vs webhooks pattern embodies this — webhooks propagate events immediately (consuming data near the change), while polling provides a safety net by periodically pulling state from the source of truth.
You're not choosing between push and pull. You're using both, each for what it does best.
When to skip hybrid
Hybrid adds operational complexity. It's not always worth it:
- Low-value data — if a stale product description corrects itself on the next sync cycle, polling alone is sufficient
- Source supports guaranteed delivery — platforms like Stripe and Twilio have built-in retry queues with configurable policies; adding your own polling sweep on top may be redundant
- Team capacity — if your team is already stretched, a well-implemented polling-only approach is better than a poorly-maintained hybrid system
Decision Framework: 5 Questions to Choose Your Strategy
Before building, answer these five questions. They'll guide you to the right trigger strategy in the polling vs webhooks decision — or confirm that hybrid is the way to go.
1. Does the source system support webhooks?
Most ERPs don't. SAP, Infor, Epicor, and many legacy systems expose query APIs but don't fire outbound events. If the source can't push, polling is your only option — and that's fine.
If no → Polling. Don't fight the source system's architecture.
2. How time-sensitive is the data?
Not all data has the same urgency:
- Inventory levels → High urgency. A customer sees "in stock" when the last unit was sold 30 seconds ago. Webhooks (with polling fallback).
- Price lists → Low urgency. Price updates propagated within an hour are acceptable for most B2B scenarios. Polling is sufficient.
- Order status → Medium urgency. Customers expect updates within minutes, not seconds. Webhooks are nice-to-have, but polling every 5 minutes often meets the SLA.
High urgency → Webhooks + polling fallback.
Low urgency → Polling only.
3. Can you guarantee webhook handler uptime?
Be honest. If your team doesn't have:
- Health monitoring on the webhook endpoint
- Automatic scaling for burst traffic
- A dead letter queue for failed processing
- Alerting for elevated error rates
...then you can't guarantee uptime. And webhooks without reliable handlers are worse than polling, because you'll think you're receiving events but silently miss them.
If no → Add a polling fallback. Always.
4. What's your team's operational maturity?
Webhooks require infrastructure that polling doesn't:
- Public HTTPS endpoints with TLS
- HMAC signature validation
- Idempotent processing with deduplication
- Dead letter queue monitoring
- Retry storm protection (inbound rate limiting)
A junior team or a team without dedicated DevOps support should start with polling and add webhooks later when the operational foundation is solid.
5. What's the failure cost?
| Missed Event | Business Impact | Recommended Strategy |
|---|---|---|
| Missed order | Lost revenue, angry customer | Hybrid (webhook + polling sweep) |
| Stale product description | Minor, corrected on next sync | Polling |
| Delayed shipment notification | Customer support tickets | Webhooks with polling fallback |
| Missed price update | Margin erosion or overcharging | Hybrid |
| Stale analytics data | Delayed reporting | Polling |
High failure cost → Hybrid. No exceptions.
Observability: How to Know Your Triggers Are Healthy
The most dangerous integration is one that fails silently. Whether you choose polling, webhooks, or hybrid, instrument these metrics:
For polling
- Sync cycle duration — track P50, P95, P99. A sudden increase means the source system is degrading or your delta is growing.
- Records processed per cycle — a sudden spike (bulk import) or drop to zero (broken cursor) are both signals.
- Consecutive empty polls — if your cron runs every 5 minutes but returns zero records for 2 hours, something may be wrong with your cursor or the source system.
- Cursor position lag — the gap between your cursor's timestamp and the current time. If this grows, your polling can't keep up.
For webhooks
- Events received per minute — baseline this. A sudden drop means the provider stopped sending, not that nothing changed.
- Signature validation failures — non-zero means either a misconfigured secret or an attack.
- Queue depth — if your processing queue grows faster than workers drain it, you're heading toward a backlog.
- Processing error rate — track by event type. A spike in
order.updatederrors but notorder.createdpoints to a specific handler bug.
For hybrid
- Recovery rate — the percentage of events caught by polling that were missed by webhooks. This is your webhook reliability score. Target: < 0.1%.
- Time-to-detection — how long between when an event occurred and when your system processed it. Webhooks should dominate; polling should rarely be the first handler.
Implementation Checklist
If you choose Polling
- Use cursor-based pagination, not offset — offsets break when data changes between pages
- Store the cursor persistently (database or Redis, not process memory)
- Process records in batches, not one-by-one — reduces overhead by 10-50x
- Implement exponential backoff on consecutive empty responses
- Log every sync cycle — timestamp, records processed, cursor position, duration
- Set up alerts for sync failures and for consecutive zero-record cycles
- Respect rate limits — use a token bucket, not unthrottled loops
- Reuse HTTP connections — connection pooling eliminates TLS handshake overhead per request
If you choose Webhooks
- Validate signatures on every request (HMAC-SHA256 with a shared secret)
- Respond 200 immediately — enqueue to a durable queue (BullMQ, RabbitMQ, SQS), process asynchronously
- Implement idempotency — deduplicate by event ID before processing
- Set up a Dead Letter Queue for events that fail after max retries
- Add a polling fallback for missed events — run a sweep every 15-30 minutes
- Protect against retry storms — rate limit your inbound webhook endpoint
- Reject stale events — discard events older than your tolerance window (e.g., > 24 hours)
- Monitor queue depth and processing latency — growing queues mean your consumers can't keep up
If you choose Hybrid (recommended)
- Webhooks trigger immediate processing via a durable queue
- Polling sweep runs every 15-30 minutes as a safety net
- Both paths converge on the same idempotent processor — no duplicate logic
- Use an event store to track which events were received via webhook vs recovered via polling
- Monitor the recovery rate — if polling catches > 1% of events, investigate the webhook path
- Alert on recovery spikes — a sudden increase in recovered events signals a provider-side incident
The Integration Maestro Perspective
Here's the rule I apply to every integration I design:
Never trust a single trigger mechanism. The best integrations have a primary trigger AND a verification sweep.
This connects to several Integration Maestro rules:
- The Idempotency Mandate — both polling and webhook handlers must be idempotent, because events will be processed more than once
- The Retry Storm Effect — webhook retries without limits can turn a small failure into a cascading outage
- The Data Gravity Rule — events should propagate close to where data changes, but verification should pull from the source of truth
- The Real-Time Illusion — most "real-time" requirements are actually "fast enough," and polling every 5 minutes is often fast enough
The polling vs webhooks debate has a simple answer once you've been burned enough times: reliability beats latency in every integration I've ever shipped. Use webhooks for speed, polling for safety, and the hybrid pattern when you can't afford to miss a single event.
The next question after choosing your trigger strategy is how to execute the sync itself at scale. For that, see How to Sync 1M Products in Under 30 Seconds — which builds directly on the patterns described here.
Want more integration architecture insights? Subscribe to the newsletter or connect with me on LinkedIn.
Enjoying this article?
Get more deep dives on integration architecture delivered to your inbox.

Integration Architect
Artemii Karkusha is an integration architect focused on ERP, eCommerce, and high-load system integrations. He writes about integration failures, architectural trade-offs, and performance patterns.
Related Articles
UCP April 2026: Cart, Catalog, and Signals Change Everything
The Universal Commerce Protocol just shipped its biggest release yet: cart management, catalog search, product lookup, and a signals framework for fraud prevention. I broke down 27 new schemas, 5 breaking changes, and the architectural implications for teams building commerce integrations.
Visa VIC vs UCP: Two Competing Visions for Agentic Commerce
Visa published their VIC reference agent — a 5-microservice demo of AI-driven shopping with tokenized payments. I dissected the architecture, compared it to UCP and other open protocols, and found a fundamental design tension: card networks optimize for payment security, open protocols optimize for merchant flexibility.
A 2 AM Integration Failure That Changed How I Design Systems Forever
Black Friday exposed a hidden architectural mistake: using eCommerce as the integration bridge. Here’s why it breaks at scale — and the rule I follow now.
Came from LinkedIn or X? Follow me there for more quick insights on integration architecture, or subscribe to the newsletter for the full deep dives.